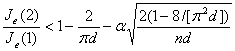
The code to perform divisive hierarchical clustering was provided by Luke Rendell (ler4 at st-andrews.ac.uk) and is described in Rendell and Whitehead (2003).
The divisive clustering algorithm (Duda et al, 2001) is based on the null hypothesis that the data is described by a single d-dimensional normally distributed sphere and it rejects this null hypothesis if splitting the data and discribing it with two spheres is significantly better. Whether splitting the data is significantly better is evaluated with the following ratio :
where n is the number of samples, d the dimension of the data, Je(1) is the error of the single cluster model and Je(2) the sum of the errors of the two cluster model,
![]()
Alpha is evaluated at the p-percent significance level

The algorithm continues splitting clusters as long as the error ratio passes the criterion at the chosen significance level.
Citations :
Duda, O.D., P.E. Hart, and D.G. Stork (2001). Pattern Classification (2nd ed.). Wiley-Interscience.
Rendell, L.E. and H.Whitehead (2003). Comparing repertoires of sperm whale codas: a multiple methods approach. The international Journal of Animal Sound and its Recordings, 14:61-81.